Hierarchical Text Classification with LLMs
From Inbox Labels to Chat Logs: A Practical Look at Hierarchical Classification

.svg)
.svg)


Hierarchical text classification extends traditional text classification by organizing labels into a tree-like structure. In this post, we revisit Ensembling Prompting Strategies for Zero-Shot Hierarchical Text Classification with Large Language Models and evaluate how more recent models perform on the same benchmark.
Text classification is a classic problem in natural language processing. Traditional approaches require training a model on a fixed set of class labels. Large Language Models (LLMs), however, can tackle this problem in a zero-shot setting. Because of their generalization capabilities, they do not require task-specific training and are not restricted to a predefined set of labels.
Hierarchical text classification appears in applications such as email inbox labelling, ticket routing. At Voker, we intend to use it to extract themes and patterns from LLM conversation logs.
Dataset
- WOS (Web of Science): A dataset of research paper abstracts with a two-level hierarchy: 7 top-level classes and 134 second-level classes. We use 4,698 samples from the full dataset.
- DBpedia: Contains 5,000 randomly sampled Wikipedia articles with three layers: 9 top-level classes, 70 mid-level classes, and 219 leaf-level classes.
- Amazon: Contains Amazon product reviews with three layers: 6 top-level classes, 64 mid-level classes, and 472 leaf-level classes. We use 5,000 samples from the full dataset.
Methods
The paper presents a number of methods but the top performing where Per-path, Per-parent, Flattened, and a path-valid method for combining multiple predictions.
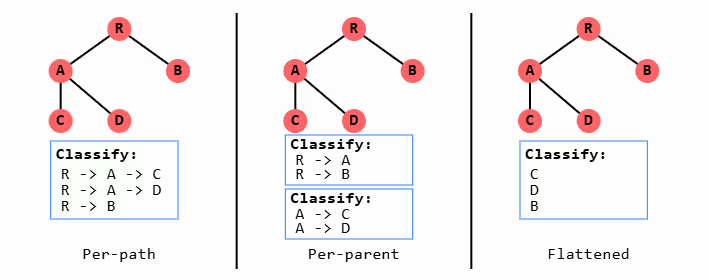
- Per-path: Constructs entire valid label paths from root to leaf and selects among them.
- Per-parent: Traverses the hierarchy one level at a time, classifying the input based only on the valid child nodes at each level.
- Flattened: Considers only leaf-node labels, ignoring intermediate structure.
Combined
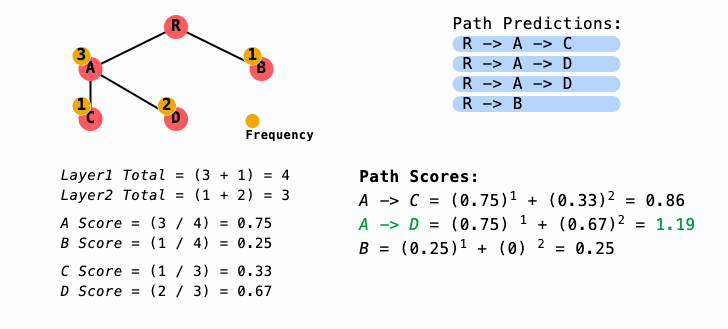
The paper proposes a path-valid method for combining predictions from multiple strategies (e.g., per-path, per-parent, flattened) as well as from multiple runs of the same strategy (e.g., across different models or repeated runs of the same model).
Selecting the most common category independently at each level can produce invalid paths. Instead, this method computes the proportion of times each node is selected across runs and chooses the path with the highest combined score over the full hierarchy.
Results
Below is a comparison of Micro-F1 (%), Macro-F1 (%) and Example-F1 (%) scores. (Each metric balances precision and recall but differs in how it accounts for class imbalance.)
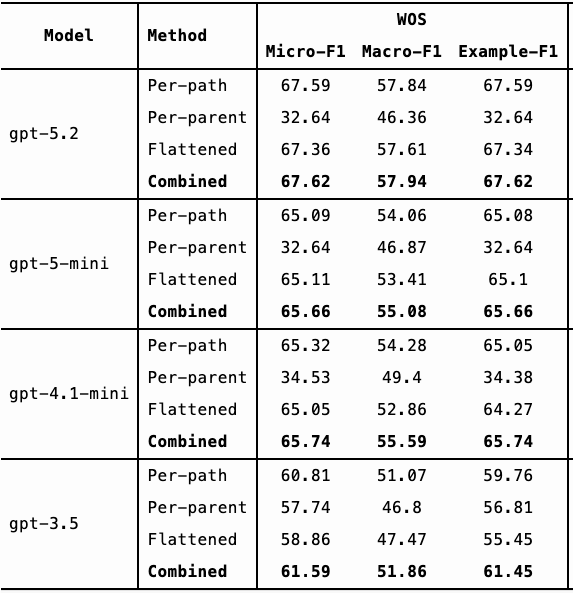
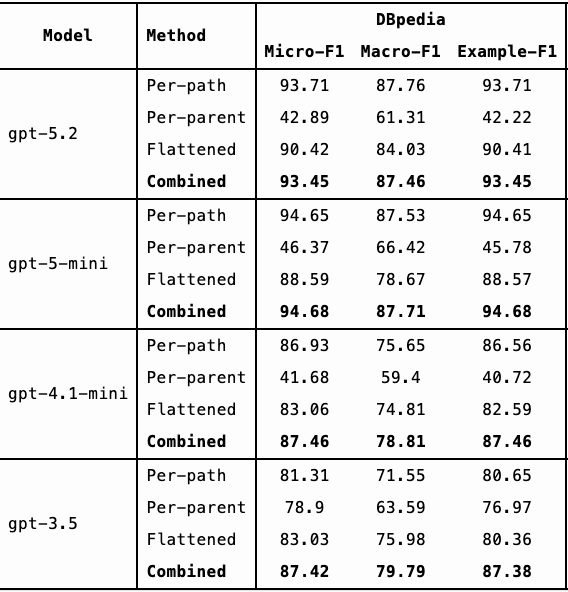
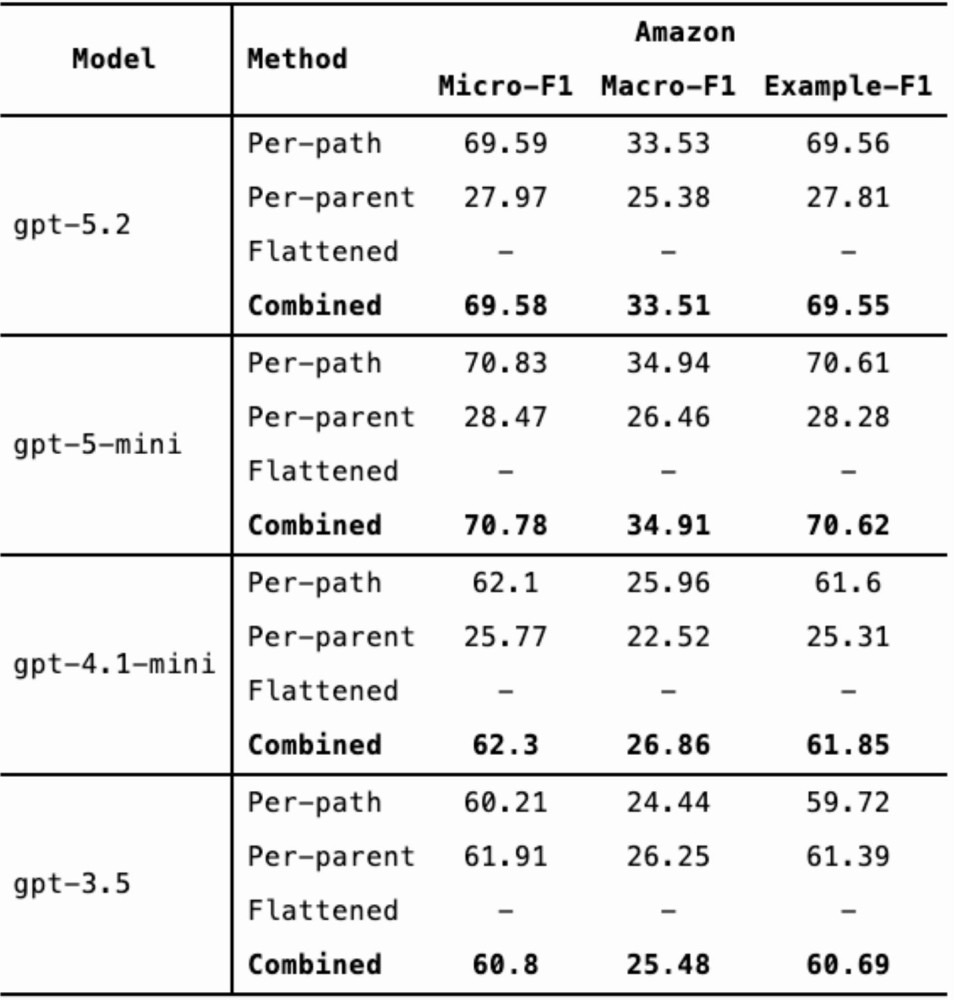
From the results, we observe:
- GPT-4.1-mini outperforms GPT-3.5 on the WOS dataset and performs comparably on DBpedia and Amazon.
- GPT-5.2 and GPT-5-mini show more substantial improvements over GPT-3.5 across all three datasets.
- GPT-5.2 and GPT-5-mini achieve similar performance overall.
Given the similar performance between GPT-5.2 and GPT-5-mini, cost and latency become important considerations. GPT-5.2 costs approximately 7x more than GPT-5-mini, but its requests complete roughly 3-4x faster.
Interestingly, GPT-4.1-mini, GPT-5-mini, and GPT-5.2 perform significantly worse using the per-parent method compared to per-path and flattened approaches. In contrast, GPT-3.5 showed more consistent performance across methods.
To further improve results, we could:
- Add additional prompting strategies
- Run each strategy multiple times
- Ensemble across multiple models
However, each additional model increases cost and potentially latency.
Next Steps
Text classification works well when categories are predefined. In our use case, classifying LLM chat logs, we may not know the appropriate categories in advance. The next step is to explore how this hierarchical approach can dynamically introduce new categories as needed.

More from the Blog

Understanding how your users use your agents as a PM
Most PMs analyze AI agent performance by dumping CSV logs into Claude or ChatGPT and hoping for insight — here are 3 prompting tactics that actually make that analysis useful.


Putting SkillOpt to the test
We tested SkillOpt (Microsoft's new self-evolving skill optimizer) on a real benchmark — starting with a 3-line skill and letting it iteratively rewrite itself over multiple training epochs.


Should you be nice to your agents?
We tested 6 tones (neutral, polite, urgent, rude, hostile, flattering) on the same hard coding prompt across OpenAI and Anthropic models.
