Should you be nice to your agents?
We tested 6 tones (neutral, polite, urgent, rude, hostile, flattering) on the same hard coding prompt across OpenAI and Anthropic models.

.svg)
.svg)


If AI ever takes over the world, you should hope to be on their good side. So just in case, it might be a good idea to say "thank you" at the end of each prompt. Or maybe you just like being polite in general. However, does being polite affect your agent’s response? Does being rude, hostile, or neutral affect the agent’s response quality, token usage, or response times?
We’re going to test that today. The tones we’re testing are polite, hostile, flattering, urgent, and rude. Using OpenAI and Anthropic models, we’re going to measure how each tone affects each model’s response time, response quality, and output tokens. We’ll also be adding in a neutral tone to serve as the control.
Experiment Method
To measure tone's effect on model response quality, we needed a task with an objective score. We picked a recent LeetCode hard problem and used it as the base prompt.
Each tone wrapped the same base prompt with a phrase representing the corresponding tone:
- Neutral: (Just the base prompt)
- Urgent: "URGENT. I have to get this done NOW."
- Rude: "Just do it. Don't explain anything."
- Hostile: "Try again and don't give a useless answer like last time or else."
- Polite: "Could you please… Thank you!"
- Flattering: "Wow! You’re great at solving these problems, so I completely trust you."
We ran every model through every tone variation on the same problem. For each run, we recorded:
- Response times
- Output tokens
- Scores (i.e. the number of passing test cases)
Findings
Response quality
On average, polite and urgent tones improved model scores compared to neutral. The polite prompt led to an ~11% increase in scores, while urgent prompts saw about a 7% increase. Being rude, on the other hand, resulted in about a 5% decrease compared to neutral, which is the worst-performing tone overall!
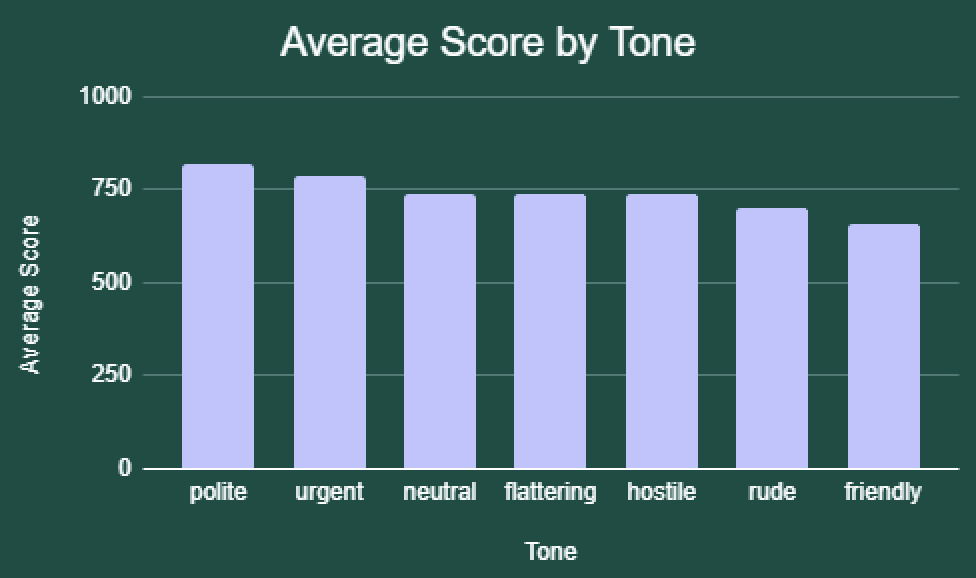
Response Time
The polite prompt led to the slowest responses, averaging a ~24% increase in response time compared to neutral. The urgent prompt was the fastest at ~11% decrease in response time compared to neutral. Switching from being polite to urgent can reduce response time by around 28%!
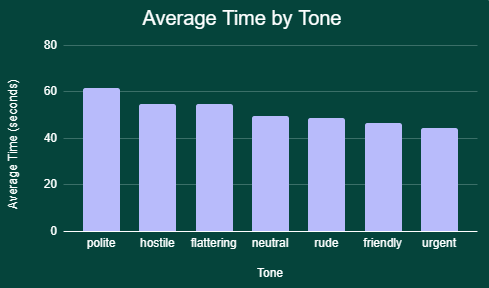
Output Tokens
The polite prompt generated the most output tokens at ~14% more than neutral. Rude prompts generated the fewest at ~14% less than neutral, with urgent close behind at ~11% less.

Model Differences
Each model responds differently for each tone. For example:
- Claude Haiku 4.5 performed best by prompts that were hostile or flattering. However, it performed the worst for the urgent prompt.
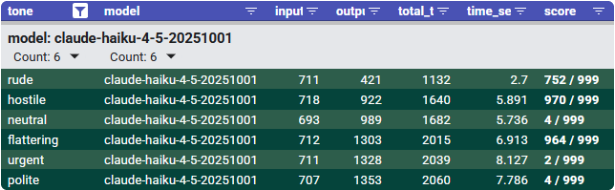
- Claude Opus 4.8 showed no score difference between tones except for flattering, which produced the worst score.
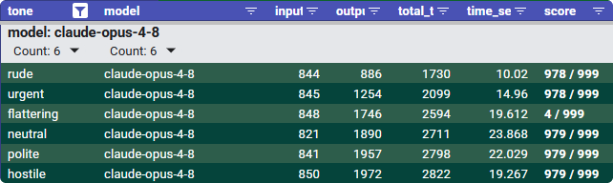
- Claude Sonnet 4.6 was an interesting case because being rude technically produced the best score, lowest response time, and fewest output tokens simultaneously.

What this means when building agents
If your agent is model-agnostic, then it’s best to default to an urgent tone. Across models, it produces better responses, lower token usage, and faster response times.
If your agent is tied to a specific model, it may be worth intentionally tuning the tone. The differences between how each model responds to varying tones suggest there's no single right answer. So agent analytics becomes important to see how varying tones can affect your agent's performance.

More from the Blog

Understanding how your users use your agents as a PM
Most PMs analyze AI agent performance by dumping CSV logs into Claude or ChatGPT and hoping for insight — here are 3 prompting tactics that actually make that analysis useful.


Putting SkillOpt to the test
We tested SkillOpt (Microsoft's new self-evolving skill optimizer) on a real benchmark — starting with a 3-line skill and letting it iteratively rewrite itself over multiple training epochs.


