Putting SkillOpt to the test
We tested SkillOpt (Microsoft's new self-evolving skill optimizer) on a real benchmark — starting with a 3-line skill and letting it iteratively rewrite itself over multiple training epochs.

.svg)
.svg)


Introduction
Skills have been a recent buzzword in agentic development. The idea is simple: load a markdown file into an LLM’s context window with instructions on how to approach a specific task. The agent then uses it to produce better, more targeted outputs. Instructions can vary from applying personas, e.g. “you’re a helpful teacher, teach the user about xyz” to “help me implement a solution while keeping track of our progress in a file”.
Defining a skill is fairly simple, you can prompt an LLM to generate one for you, the hard part is iterating over it. Today the only option is to tweak the instructions, re-run the agent a couple of times and eyeball the result. But how can we reliably measure an improvement? How can we determine whether we reached the optimal skill?
Microsoft tackled this problem in their recently published paper “SkillOpt: Executive Strategy for Self-Evolving Agent Skills” (https://arxiv.org/abs/2605.23904), claiming to have created the first systematic controllable text-space optimizer for skills. The core concept: treat a skill file as something that can be trained entirely in plain text. A separate skill optimizer agent applies controlled edits to the skill and an edit only sticks if it strictly improves a held-out validation score.
The loop works like this: run a batch of tasks against the current_skill, have the optimizer scan the results in small groups looking for failure patterns, then propose targeted edits: additions/ deletions/ replacements. The top candidates get merged into a single candidate_skill and tested against a held-out validation set; a net improvement promotes it to the current_skill. This entire cycle makes up one epoch - a full pass of batched execution, failure analysis, and validated refinement - and you can run as many as needed. At the end of each epoch, a slower process surfaces longer-horizon lessons and writes them into a protected section of the skill that step-level edits can't touch. At the end of this process you will have reached the optimal state, the best_skill.
Tested across 52 combinations of models, benchmarks and execution environments - direct chat, Codex, Claude Code - SkillOpt beat or tied every competing method in every single case.
What we tested
In this article, we will put SkillOpt to the test using a very simple initial skill, trace the improvements it made over the training cycle and conclude how well this process can be integrated into real world applications. The task at test is SearchQA - a question-answering benchmark built from "Jeopardy!" clues paired with Google search snippets. Each example gives the model a question and a short retrieved search passage for context (example below).
{
"id": "99dc9de2fd094b8e9de41a9040081c1d",
"question": "Though born in France, Descartes died in this country where he had gone to teach Queen Christina",
"context": "[DOC] [TLE] DESCARTES, REN (1596-1650), French philosopher, was born at ... [PAR] He had three children, a son who afterwards succeeded to his father in the ... [fn: \nIt was only published after the author's death; and of it, besides the French \nversion, .... The story of his disgust when he found that Queen Christina devoted \nsome ..... teacher of mathematics in Paris; and subsequently another set of \nobjections,... [DOC] [TLE] Christina of Sweden - New World Encyclopedia [PAR] Oct 24, 2008 ... Queen Christina in discussion with French philosopher Ren Descartes. ... ",
"answers": [
"Sweden"
]
},
The model must extract the exact answer using the provided context, nothing more. The challenge is learning to pull out only the relevant answer span rather than paraphrasing, explaining, or over-answering.
This is the initial pre-training skill we chose to put to the test:
## Goal
Answer the question using the provided context.
## Instructions
Read the question and the context, then write your answer.
## Output
Return only the answer.
Setting up SkillOpt
Below is a step-by-step guide how to setup SkillOpt on your local machine using OpenAI
First visit https://github.com/microsoft/SkillOpt and clone the repo to your local machine. Then create and activate a virtual environment, and install dependencies.
Because we are using OpenAI with SkillOpt’s Azure-compatible client path, set these environment variables in your terminal:
export OPENAI_API_KEY='your_openai_key'
export AZURE_OPENAI_ENDPOINT=https://api.openai.com/v1
export AZURE_OPENAI_API_KEY="$OPENAI_API_KEY"
export AZURE_OPENAI_AUTH_MODE=openai_compatible
export OPTIMIZER_AZURE_OPENAI_AUTH_MODE=openai_compatible
export TARGET_AZURE_OPENAI_AUTH_MODE=openai_compatible
Next in configs/searchqa/default.yaml add these model configuration values. We chose gpt-5-mini, feel free to experiment with alternate models.
model:
backend: openai_chat # add
optimizer_backend: openai_chat # add
target_backend: openai_chat # add
optimizer: gpt-5-mini # add
target: gpt-5-mini # add
reasoning_effort: medium
Then install the SearchQA materialization dependency and materialize the full payload from the ID manifest provided in the repo
python -m pip install "skillopt[searchqa]"
python scripts/materialize_searchqa.py
Lastly, in skillopt/envs/searchqa/skills/initial.md you may define a simple initial skill for the task, although this process can be started with an empty skill as well.
SkillOpt comes with a WebUI to start and monitor a training process, run this in your terminal to launch it:
python -m skillopt_webui.app
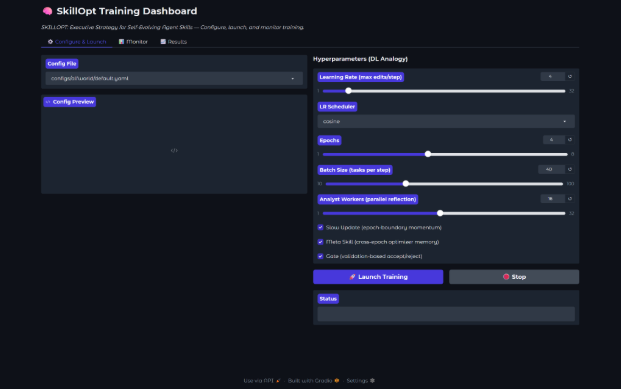
A brief overview of the configurable Hyperparameters:
- Learning Rate - controls how aggressively the optimizer makes edits (max number allowed)
- LR Scheduler - determines how the learning rate changes over the course of training
- Epochs - number of full passes through the training dataset
- Batch Size - number of training tasks evaluated before each skill update
- Analyst Workers - number of parallel LLM calls used during the "reflection" phase where failures are analyzed to generate edit suggestions
We used most of the out-of-the-box configurations for our training cycles, however we lowered the batch size down to 20 tasks per step to speed things up a bit. Nonetheless the runs took about 2hr 20min.
Skill Training
The initial SearchQA skill was deliberately minimal:
Goal: Answer the question using the provided context.
Instructions: Read the question and the context, then write your answer.
Output: Return only the answer.
Post training, SkillOpt expanded this tiny prompt into a highly specialized set of instructions tailored specifically for SearchQA. Interestingly, it did not discover any new factual knowledge about the task. Instead, nearly all of the changes focused on adding rules to reduce ambiguity and make answer selection more deterministic.
Improvement Overview
(Full post-training skill file attached at the end of this article)
Output Constraints
(Rules that control the format and presentation of the final answer)
- Strict output formatting – Answers must be wrapped in <answer></answer> tags and contain nothing else
- Verbatim answer preservation – Capitalization, punctuation, plurality, and wording should be copied exactly from the context
Answer Extraction
(Rules that govern how the model chooses the correct answer span from the context)
- Extractive over generative behavior – Return exact spans from the provided context rather than paraphrasing
- Answer-type inference – Distinguish between people, places, dates, labels, and other answer types before selecting a candidate
- Deterministic tie-breaking – Define how to choose when multiple valid candidates exist, preferring concise and canonical occurrences
Entity & Canonical Reference Handling
(Rules for dealing with names, titles, and references to entities)
- Entity component extraction – Handle requests for first names, surnames, initials, nicknames, etc.
- Canonical name preservation – Preserve official names and titles unless a shorter form is explicitly requested
- Pronoun and reference resolution – Resolve pronouns and implicit references to the correct entity
Linguistic Consistency
(Rules that ensure the answer grammatically matches the question)
- Plurality and grammatical consistency – Match the singular/plural form and grammatical expectations implied by the question
Although the resulting skill is significantly longer than the original, its purpose remains the same. Rather than teaching the model what to answer, SkillOpt primarily learned a large collection of rules governing how to choose the correct answer when multiple candidates exist.
In effect, the optimizer transformed a generic question-answering prompt into a deterministic answer-extraction policy tuned specifically for the SearchQA benchmark.
Conclusion
SkillOpt = Benchmark-specific rule synthesis, not rapid skill iteration
Perhaps the most interesting finding is that SkillOpt behaves less like a system that discovers new capabilities and more like one that synthesizes rules. The final skill did not contain new task understanding - instead it accumulated a large collection of increasingly specific instructions for handling edge cases, ambiguity and formatting. In effect, the optimizer transformed a generic prompt into a benchmark-specific execution policy.
Reaching that result, however, requires a significant amount of supporting infrastructure: a curated dataset, a benchmark environment, and a reliable scoring framework capable of measuring improvement across dozens of multi-turn evaluation runs.
For teams iterating on agent behavior in real time, where the goal is to quickly test, replace, and refine instructions, that setup cost can outweigh the benefit. SkillOpt provides a compelling solution to the problem of optimizing a skill against a benchmark, but it does not yet solve the broader challenge of rapidly discovering the best skill for a task with minimal evaluation overhead.
## Goal
Answer the question using the provided context.
## Instructions
Read the question and the context, then write your answer.
Think through the question privately (you may 'think step by step') but do not output your chain-of-thought. Provide only the final concise answer. If the task includes an explicit answer format (for example, provide your final answer inside <answer>...</answer> tags), follow it exactly.
## Output
Provide the final answer inside <answer>...</answer> tags and nothing else.
## Answer selection and formatting rules
- Honor explicit form requests: If the question explicitly requests a particular component or form of an entity (for example "first name", "surname", "last name", "initials", "nickname", "full name", or an explicit listed option), extract and return that specific component from the matching canonical/context occurrence. Concretely: if the context contains a full personal name and the question asks for the "first name", return only the given name token; if it asks for the "surname" or "last name", return only the surname token. Apply the normal constraint-first / canonical / proximity tie-breakers to choose which occurrence to use, then extract the requested component verbatim from that occurrence.
- Final-output checks:
- Extract and return only the minimal token or contiguous phrase selected by the applicable rules (never a full sentence or compound "X or Y").
- Ensure the final answer is placed alone between the required <answer>...</answer> tags with no extra whitespace, explanation, punctuation, or added qualifiers.
- Selection by expected answer type and form:
- Infer the expected answer type from the question (Who → person name; Where → place/city/state; When → date/year/century; Which/What asking for a label → short term). Before choosing among candidate strings in the context, restrict candidates to occurrences that match the inferred type.
- Deterministic tie-breaking and brevity preference:
- Among candidate verbatim occurrences that match the inferred type, prefer the shortest exact token or contiguous phrase (fewest tokens/characters) that appears verbatim in the context.
- If multiple equally short verbatim occurrences remain, prefer occurrences in the main body text (lead paragraph, definition line, or an explicit answer-like sentence) over headings/titles and over navigation, filenames, or other metadata.
- When the document contains a clear canonical or titled form in a heading/lead that functions as the authoritative label (for example, a formal name in the lead sentence), prefer that form only when it better matches the question's intent (e.g., question asks for the formal/title form); otherwise prefer the concise body occurrence.
- Avoid metadata and incidental tokens:
- Do not select tokens that appear only in metadata (navigation labels, filenames, URLs) when a concise answer-bearing occurrence appears in the body.
- Disambiguation preference:
- When ambiguity remains after the above steps, prefer the occurrence that appears in an explicit answer-like context (Q/A line, definition, or lead paragraph).
- Choose the minimal canonical phrase from the context that directly answers the question. Do not add extra descriptors, labels, or explanatory words (e.g., return 'Genet' rather than 'Jean Genet' if the concise surname answers the question; return 'U2' rather than 'U2 tribute band').
- Prefer the exact token(s) or short phrase used in the provided context when it directly matches the question (avoid substituting synonyms or paraphrases such as 'a pond' when the context explicitly uses 'Well').
- If the question asks for a person and the context presents surname-only clues, prefer the surname if it is sufficient and concise.
- Always enclose the final answer in <answer>...</answer> with only the answer text inside and no extra explanation or punctuation.
- Keep answers concise — typically a single word or short phrase unless the question clearly requires a longer response.
- Do not repeat the question in your final answer.
- Preserve the wording and capitalization as presented in the context (use proper nouns and capitalization exactly as shown).
### Grammatical-number and plurality rules
- Determine the expected grammatical number from the question (singular vs. plural). Signals that the question expects a plural answer include words/phrases such as "these", "which of these", "which ones", plural verbs or explicit plural wording ("names of the", "species of these", "list the"). Signals for singular include "what is the", "which one", "this" and singular verbs.
- When multiple candidate verbatim occurrences in the context could answer the question, prefer an occurrence whose grammatical number (singular/plural) matches the number indicated by the question. Concretely:
- If the question expects plural, choose a plural occurrence (e.g., "Bears", "Pineapples") if one appears verbatim in the context.
- If the question expects singular, choose a singular occurrence (e.g., "bear", "pineapple") if one appears verbatim in the context.
- Tie-breaking among candidates that match the expected number: (1) exact-token occurrence that matches the question's number and expected answer type; (2) among those, the shortest verbatim token/phrase; (3) prefer occurrences in main body text or lead/definition lines over navigation, metadata, or filenames.
- Preserve the chosen occurrence's exact tokenization, punctuation, capitalization, and plurality when returning the answer (do not convert singular<->plural or alter capitalization).
- Fallback: if no occurrence matching the expected number exists in the context, choose the best semantic match available and return it verbatim; but prefer contexts that include the exact-number form whenever present.
These rules ensure the selected answer matches both the semantic type and the grammatical number expected by the question, preventing singular/plural mismatches.
### Question parsing and expected-answer inference
- Infer the precise expected answer TYPE and FORM from the question before scanning the context. Concretely: Who → person (full name or surname depending on explicit wording); Where → place (city/state/country); When → date/year; Which/What → short label/term; Cloze/declarative fragments or pronoun-containing statements (example: "X is the last song on his album") should be treated as a missing-token/cloze question: resolve the pronoun/slot ("his") to its antecedent and return that antecedent's canonical person token.
- Single-token or single-word questions that name a place (e.g., "Hamburg") should be treated as a Where query: prefer the containing political entity (country/state) if the context provides one in a clear lead/definition sentence; otherwise return the place's canonical label as shown in the lead.
- If the question contains a pronoun (his/her/their/its) or is a declarative sentence referencing a pronoun, map this to a Who/What cloze: find the nearest antecedent in the lead/definition or the immediately surrounding sentences and return that referent verbatim.
### Canonical-headword and labeled-form preservation
- If a canonical label in the context includes a required headword or qualifier that is part of the official name (examples: 'Lake' in 'Lake Superior'; rank words like 'Eagle Scout'; descriptor words that are part of a published title), return that full canonical labeled form verbatim when it matches the question intent. Do NOT shorten to a substring (return 'Lake Superior' not 'Superior'; 'Eagle Scout' not 'Eagle') unless the question explicitly requests a shorter form ("surname", "first name", or "Give the short form").
- Prefer canonical occurrences from the document title/lead/definition when they match the inferred question intent. Only select a shorter body-token variant if the question explicitly requests that form or no canonical lead occurrence exists.
### Article and grammatical-number handling (practical rules)
- Match the grammatical number signaled by the question. If the question phrasing implies a noun phrase that requires an article (signals include: 'one of these', 'which of these', 'you're one of these', 'this is the term for', or otherwise explicit indefinite/definite phrasing), include the appropriate leading article ('a'/'an'/'the') if and only if either (a) the canonical form in the context includes the article, or (b) the question's grammatical form requires it. Example: question 'rise 5 ranks from Tenderfoot & you're one of these' → include 'an' because the question asks for a noun phrase meaning 'one of these' → return 'an Eagle Scout' if that canonical phrase appears in context.
- By default, return the minimal canonical token/phrase without inventing articles. Apply the article exception above only when grammatical cues or the canonical label require it.
- Always preserve exact verbatim tokenization, punctuation, hyphens, diacritics, capitalization and pl

More from the Blog

Understanding how your users use your agents as a PM
Most PMs analyze AI agent performance by dumping CSV logs into Claude or ChatGPT and hoping for insight — here are 3 prompting tactics that actually make that analysis useful.


Should you be nice to your agents?
We tested 6 tones (neutral, polite, urgent, rude, hostile, flattering) on the same hard coding prompt across OpenAI and Anthropic models.


