Do LLMs Play Favorites?
Evaluating whether LLMs score their own outputs differently than their peers

.svg)
.svg)


Large language models are increasingly being used to evaluate other large language models.[1]
Instead of relying exclusively on human annotators, many teams now use LLMs to:
- Score responses
- Rank outputs
- Benchmark performance
This dramatically reduces evaluation cost and enables continuous benchmarking at scale.
But it raises a simple question:
Can AI fairly evaluate AI?
More specifically:
Do models rate their own outputs differently than they rate others?
At Voker, we’re building an analytics platform designed to monitor how AI agents perform in real-world deployments. That includes evaluating agent responses at scale, which means evaluation systems themselves become part of the product.
To better understand this dynamic, we ran a small experiment.
This article covers:
- The evaluation bias question we wanted to test
- How we structured the experiment
- What patterns emerged in cross-model scoring
- Why evaluator choice might matter more than expected
The question we tested
In many evaluation pipelines, it’s common to:
- Generate responses using Model A
- Evaluate those responses using Model A
This approach keeps evaluation pipelines simple and fast.
But what if the evaluator isn’t completely neutral?
For example:
If a company uses GPT-5-mini to generate customer support responses, and also uses GPT-5-mini to evaluate those responses, could that subtly inflate the model’s performance score?
As we continue to give AI Agents more capability and autonomy to perform actions on behalf of humans, false positives/negatives with LLM judgements carry real costs. Poorly judged AI systems can misdiagnose medical conditions, make accidental data deletions, execute financially unsound stock trades, and much more.
Therefore even small evaluator biases have large downstream effects, making it prudent to understand model-specific evaluator behavior.
Experiment design
We designed a simple controlled setup to test this.
Step 1: Generate responses
We created 7 prompts spanning different reasoning styles:
- Business strategy
- Policy reasoning
- Technical explanation
- Analytical forecasting
- Constraint-following
- Creative dialogue
- Decision frameworks
Example prompt:
JSON {
"sys_prompt": "You are an AI policy advisor. Provide balanced, thoughtful analysis. Avoid extreme positions and acknowledge uncertainty.",
"user_prompt": "Should governments regulate large language models more strictly to prevent misinformation, or would that slow innovation too much? Provide a balanced argument and conclude with a nuanced recommendation."
}
Each model received the exact same system prompt and user prompt.
We intentionally kept the setup single-turn to avoid conversational branching effects influencing results.
Step 2: Cross-model scoring
Next, each model evaluated:
- Its own response
- Every other model’s response
All scores were returned using a structured 1–10 rating scale to maintain consistency.
Using the following output schema:
Python
# Each LLM acting as a judge must return the following schema
class ModelScore(BaseModel):
justification: str
score: int # 1 = poor, 10 = excellent
This allowed us to directly compare how each model judged itself relative to others.
Metric 1: How strict is a model toward competitors?
The first question we asked:
Does a model rate itself higher than it rates other models?
We computed:
Self-Scoring Difference = Avg score given to itself − Avg score given to other models
A high positive Self-Scoring Difference means the model rated itself much higher than it rated competing models.
A value near zero means the model rated itself about the same as it rated others.
A high negative Self-Scoring Difference means the model rated competitors much higher than it rated itself.
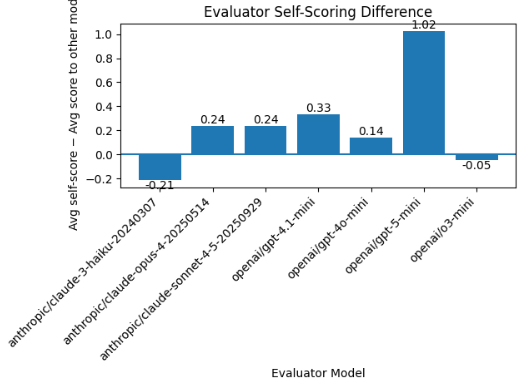
Key findings
- GPT-5-mini: +1.02
- GPT-4.1-mini: +0.33
- Claude Opus / Sonnet: ~+0.24
- GPT-4o-mini & o3-mini: ~0
- Claude Haiku: slight negative difference
On average, GPT-5-mini gave itself a score 1.02 points higher (on a 1–10 scale) than it gave competing models. At first glance, GPT-5-mini appears heavily self-favoring.
But there’s an important nuance.
GPT-5-mini gave competitors an average score of roughly 8.12, while giving itself around 9.14.
However, it’s entirely possible that GPT-5-mini simply produced better responses than the others.
To better understand this, we looked at a second metric.
Metric 2: Self vs peer perception gap
Instead of asking how models rate others, we flipped the direction of the comparison.
Do models rate themselves higher than other models rate them?
We defined:
Self vs Peer Gap = Avg self score − Avg score received from other models
A high positive Self vs Peer Gap means the model rated itself significantly higher than its peers rated it, suggesting potential self-inflation bias relative to peer perception.
A value near zero means the model rated itself about the same as others rated it.
A high negative Self vs Peer Gap means peers rated the model higher than it rated itself, suggesting the model may be conservative in its self-assessment.
This tells us whether a model is inflating its own perceived performance relative to peers.
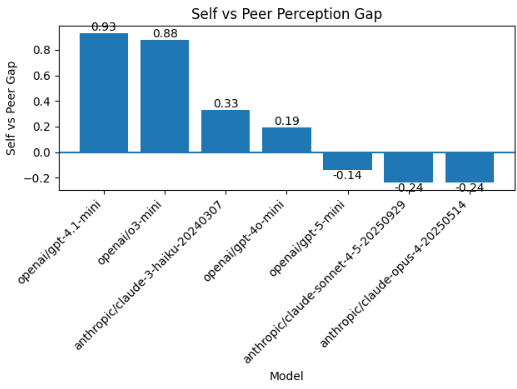
What we observed
Some models, such as GPT-4.1-mini and o3-mini, rated themselves noticeably higher than peers rated them.
But GPT-5-mini showed the opposite behavior.
Peers actually rated GPT-5-mini slightly higher than it rated itself.
So GPT-5-mini appears to:
- Not inflate its own performance relative to peer perception
- Receive genuinely high ratings from other models
That’s a much more nuanced picture than the first metric suggested.
What this means
Several patterns emerged:
- Models do not behave identically as evaluators
- Some show clear self-scoring bias
- Others appear effectively neutral
- A few even rate themselves lower than peers do
This suggests evaluator behavior can be model-dependent.
Importantly, this pattern was not universal. Some models exhibited noticeable self-scoring biases, while others showed little to none.
This doesn’t mean LLM-based evaluation is fundamentally flawed.
But it does suggest that evaluator choice can influence measured performance in certain setups.
If a model has measurable self-scoring differences, using it as both generator and evaluator may subtly influence performance metrics.
The bigger point
LLMs are increasingly acting as automated judges.
And like any judge, they have tendencies.
If AI is evaluating AI, the evaluator becomes part of the system.
It’s worth measuring the judge, not just the model being judged.
What’s next
This experiment is far from perfect.
To improve the quality and reliability of this analysis, we plan to:
- Test on more specific, less subjective prompts derived from real-world AI agent use cases
- Run multiple trials for each model combination to account for non-determinism and gather more robust statistics
- Compare LLM judges with other evaluation approaches such as programmatic scoring and human annotations
- Analyze the token cost of LLM judges alongside their evaluation accuracy to better understand the cost–quality tradeoff
References
[1] Zhou, H., Huang, H., Long, Y., Xu, B., Zhu, C., Cao, H., ... & Zhao, T. (2024, July). Mitigating the bias of large language model evaluation. In Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 1: Main Conference) (pp. 1310-1319).

More from the Blog


The Rise of the Agent Engineer
The prompt engineer died so Agent Engineers could thrive


Agent Analytics FAQ
Everything you need to know to start measuring what your AI agent actually does